Building J2EE Web Applications with UTF-8 Support
Recently, I’ve spent some time developing a little website project and I wanted it to support multiple languages and character sets with Unicode from the beginning. This turned out to be harder than I anticipated, but is actually not a big deal now that it’s done. Mainly, the problem was documentation - the lack of it, rather. Since my application is based on J2EE, you’ll have to extrapolate for different platforms if that’s not what you are using.
The first thing you need to do is ensure that your entire stack supports UTF-8 , which is a subset of Unicode that probably is good enough to handle all of your needs. For example, my application stack is Apache , Jetty , Struts , Hibernate and MySQL . I’ll save you the trouble of having to determine the level of Unicode support in all of these components by informing you that UTF-8 happily exists inside these layers.
Getting Data Out
The simple case is getting data out of the database and on to your browser’s screen. If you’re just writing your application, you’ll need to artifically populate your database with some sample text for this experiment. I found a lovely web page with all sorts of UTF-8 text in several languages, so copy/paste some of that text and get it into your database somehow. In fact, I’ll save you the trouble by providing you with some Tamil text (chosen because my closest Indian friends speak Tamil!):
வணக்கம்! நான் உங்கள் வலைப்பூவிற்கு வரவேற்கிறேன். இது UTF-8 மற்றும் தமிழ் மொழிக்கு முழு ஆதரவைக் கொண்டுள்ளது.
Note: while Firefox and MSIE can display this Tamil text alright, Feedreader isn’t able to…
Now, if you’re using MySQL Control Center or MySQL Query Browser , you should know up front that while MySQL seems to have super UTF-8 support , neither of these tools do. Actually, Control Center seems to display UTF-8 text properly right after you paste it in, but the same text appears garbled as soon as you use SQL to get the data out. MySQL Query Browser displays the text in some incomprehensible fashion in all cases:
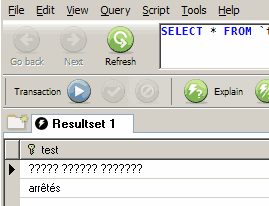
Notice, however, that it is able to properly display ISO-8859-1 text.
I had to determine that my eyes weren’t going fuzzy by using message digests to see if the data was still intact:
select md5(text_column), text_column from mytable
I stored the same text in a file on my disk and md5sum ’d that file to ensure that the digests were identical. Seems kind of a silly incompatibility for MySQL to release such a kickass database server without the proper support for UTF-8 in their admin tools.
Within Java, all java.lang.String objects are UTF-8. That’s quite cool, because it means that we can get data out of the database using Hibernate (sorry, I can’t be bothered writing SQL anymore), pass it through a Struts Action (the C in MVC
) and out into a JSP (the V in MVC).
The JSP needs to be configured a little bit, though. It needs the following declaration at the beginning of the file:
<%@ page contentType="text/html; charset=utf-8" pageEncoding="UTF-8"%>
That makes sure that the right value in the Content-Type header precedes the text/html content. For the record, this header displays as follows (use LiveHTTPHeaders for your Moz/Firefox browser to watch the headers):
Content-Type: text/html; charset=utf-8
You also need this tag in the < head> of your HTML document:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
This is less important in the cases where your application only provides character data in UTF-8. This convention exists because, based on a given static web page sitting on disk, a webserver cannot figure out the character encoding used therein. You can use things like mod_magic to figue out what kind of data is in the file, but it’s not smart enough to reliably determine the character set.
Getting Data In
So while getting data out of the database and through the stack is fairly straightforward, getting data from the browser turns out to be slightly more complicated. Data is usually transmitted from browsers to webservers using either the GET or POST methods in HTTP. (Yes, there’s more to HTTP than GET or POST, but when was the last time you wrote a webapp that used them?)
Typical use of a POST request will involve a webform that gets filled out by the user in their browser and then is sent to the server. How are you supposed to know what character set the user used while filling out the form? According to the HTML 4.01 specification, if you don’t specify the accept-charset
attribute of the < form> tag:
The default value for this attribute is the reserved string “UNKNOWN”. User agents may interpret this value as the character encoding that was used to transmit the document containing this FORM element.
So barring a buggy browser client, you can constrain your form submission to the character set(s) specified in the accept-charset attribute. In my case, I decided to be explicit by specifying “UTF-8” as the value, rather than rely on the browser to take the default (also UTF-8, since that’s how the web page with the form was encoded).
When the user submits the form, the data is sent to our server via HTTP POST, at which point it is up to our application to process the submission. Typically, in Java-land, we build webapps on frameworks (like Struts, Spring, etc.) that sit on top of the Servlet API . The servlet API defines a number of objects that your chosen servlet container will make available to you, such as ServletRequest and ServletResponse which, predictably enough, are used to model the request and response of any HTTP request (well, the HttpServletRequest and HttpServletResponse are the HTTP-specific subclasses that we’re interested in). The ServletRequest defines many abstract methods including this:
abstract public void setCharacterEncoding(String arg) throws java.io.UnsupportedEncodingException;
At this point, the astute reader will realise that this is exactly what we need to call on every servlet-derived method that will handle requests for our application. In Struts, subclasses of Action handle HTTP requests. The method signature of the execute() method of Action looks like this:
abstract public ActionForward execute(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response) throws Exception;
So the necessary work required to get Struts to process request parameters encoded with UTF-8 is exactly the same as for regular Servlet requests:
request.setCharacterEncoding("UTF-8");
Kind of tedious, no? Well, I thought so until I found a lovely little servlet filter squirreled away
in the CVS tree for Tomcat 4.0. You can configure the servlet in your web application’s web.xml descriptor with two parameters for conditionally or unconditionally setting the charater set on the current request’s request object:
< filter>
< filter-name>Set Character Encoding< /filter-name>
< filter-class >com.foo.filters.SetCharacterEncodingFilter < /filter-class>
< init-param >
< param-name>encoding< /param-name>
< param-value>UTF-8< /param-value>
< /init-param>
< init-param>
< param-name>ignore< /param-name>
< param-value>false< /param-value>
< /init-param>
< /filter>
Now, there is one gotcha here and it has to do with the handling of GET requests. Let’s say that you expose the following URL on your site with some Japanese characters stuck as part of the URI. Go ahead and click on it.
Presumably, your browser URL-encoded the request as follows:
https://www.whirlycott.com/phil/%E4%BC%8A%E6%9D%B1%E5%B1%8B%E3…..
No big deal. This type of decoding should be handled by your servlet container. The gotcha is this, though. If you do an internal forward from the servlet that intercepts the request to another servlet with the URL-encoded text as part of the rewritten URI, you need to re-encode the URI before the forward.
In other words, if your application receives a request for this:
http://www.foo.com/something/ 伊東屋ホームページ
… which in turn results in a forward to this:
… then you will have to re-URL-encode the 伊東屋ホームページ part of the request before you do the internal forward. This seems wrong to me. I’m almost wondering if part of my application stack has some kind of bug somewhere, but I haven’t investigated that possibility. Nonetheless, this step was necessary for part of my application to function.
W3C provides some Java code here that you can take for the purpose of URL encoding and decoding strings.
Building support for UTF-8 feels good because it’s the right way to build modern applications. And since it’s much easier to start off using UTF-8 than convert later, there’s hardly any reason not to do this from the beginning.